|
Computer Vision | Machine Learning I am a Machine Learning Scientist at Piñata Farms, focused on machine learning for video understanding and recommendations. I completed my PhD with Andrea Vedaldi and João Henriques in the VGG group, at the University of Oxford. I was fortunate enough to be funded by a Rhodes Scholarship and AIMS. Before that, I did my undergrad at Harvard College, where I obtained a B.A with honors in computer science.
Email / Google Scholar / Github / Twitter / LinkedIn / Thesis |

|
|
|
|
I'm interested in computer vision, self-supervised learning and multi-modal learning. |
|
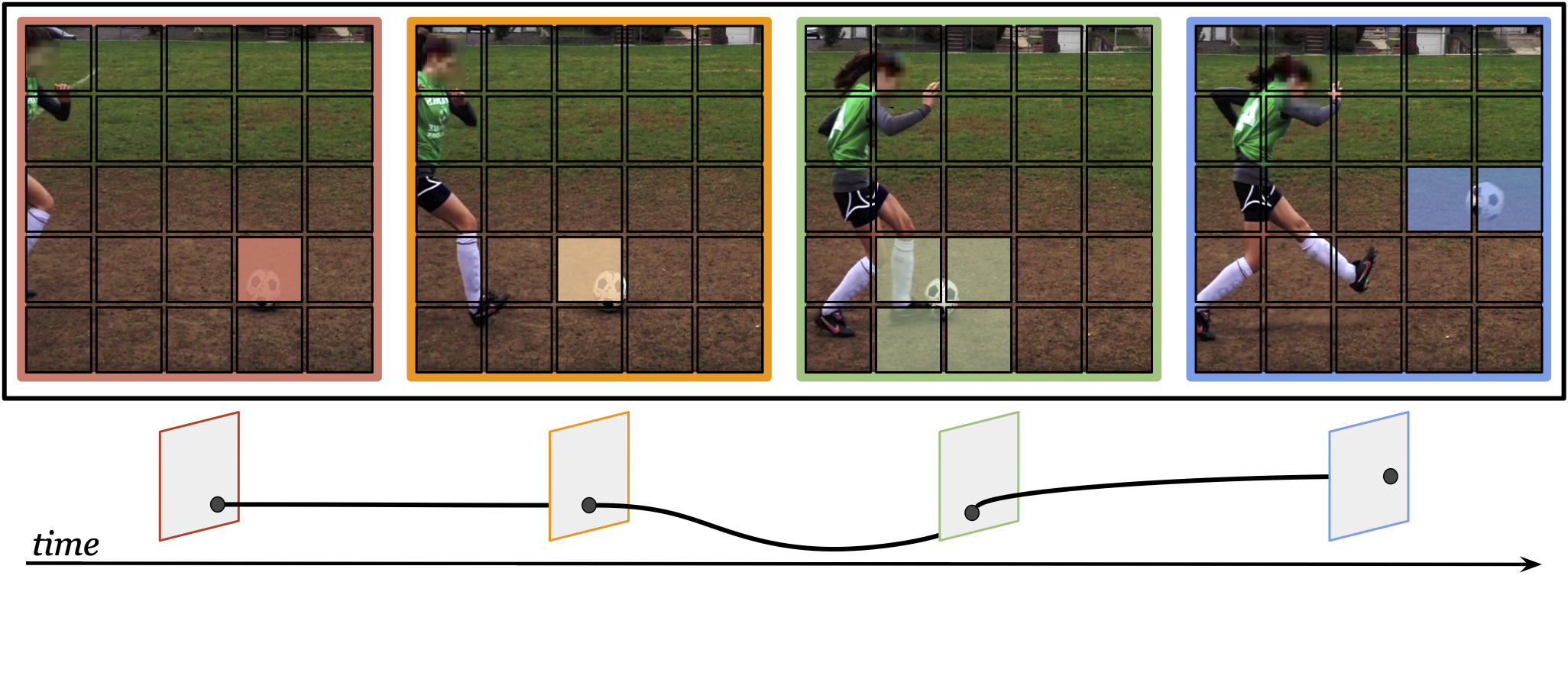
Mandela Patrick*, Dylan Campbell*, Yuki M. Asano*, Ishan Misra, Florian Metze, Christoph Feichtenhofer, Andrea Vedaldi, João F. Henriques NeurIPS, 2021 (Oral) code | slides | poster | bibtex | talk We present trajectory attention, a drop-in self-attention block for video transformers that implicitly tracks space-time patches along motion paths. We set SOTA results on a number of action recognition datasets: Kinetics-400, Something-Something V2, and Epic-Kitchens. |
|
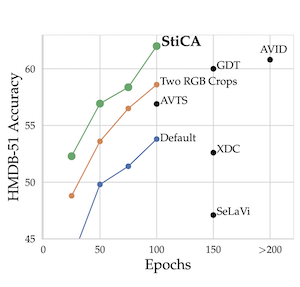
Mandela Patrick*, Yuki M. Asano*, Bernie Huang*, Ishan Misra, Florian Metze, João F. Henriques, Andrea Vedaldi ICCV, 2021 code | slides | poster | bibtex We better leverage latent time and space for video representation learning by computing efficient multi-crops in embedding space and using a shallow transformer to model time. This yields SOTA performance and allows for training with longer videos. |
|
Mandela Patrick*, Yuki M. Asano*, Polina Kuznetsova, Ruth Fong, João F. Henriques, Geoffrey Zweig, Andrea Vedaldi ICCV, 2021 code | slides | poster | bibtex | blog We give transformations the prominence they deserve by introducing a systematic framework suitable for contrastive learning. SOTA video representation learning by learning (in)variances systematically. |
|
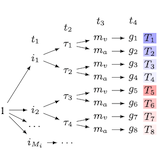
Po-Yao Huang*, Mandela Patrick*, Junjie Hu, Graham Neubig, Florian Metze, Alexander Hauptmann NAACL, 2021 code | slides | poster | bibtex We develop a transformer model to learn contextualized multilingual multimodal embedddings and also release a new multilingual instructional video dataset (MultiHowTo100M) for pre-training. We apply this model in a zero-shot setting to retrieve videos with non-English queries, and outperform recent baselines by a large margin in multilingual text-to-video search on VTT and VATEX; as well as in multilingual text-to-image search on Multi30K. |
|
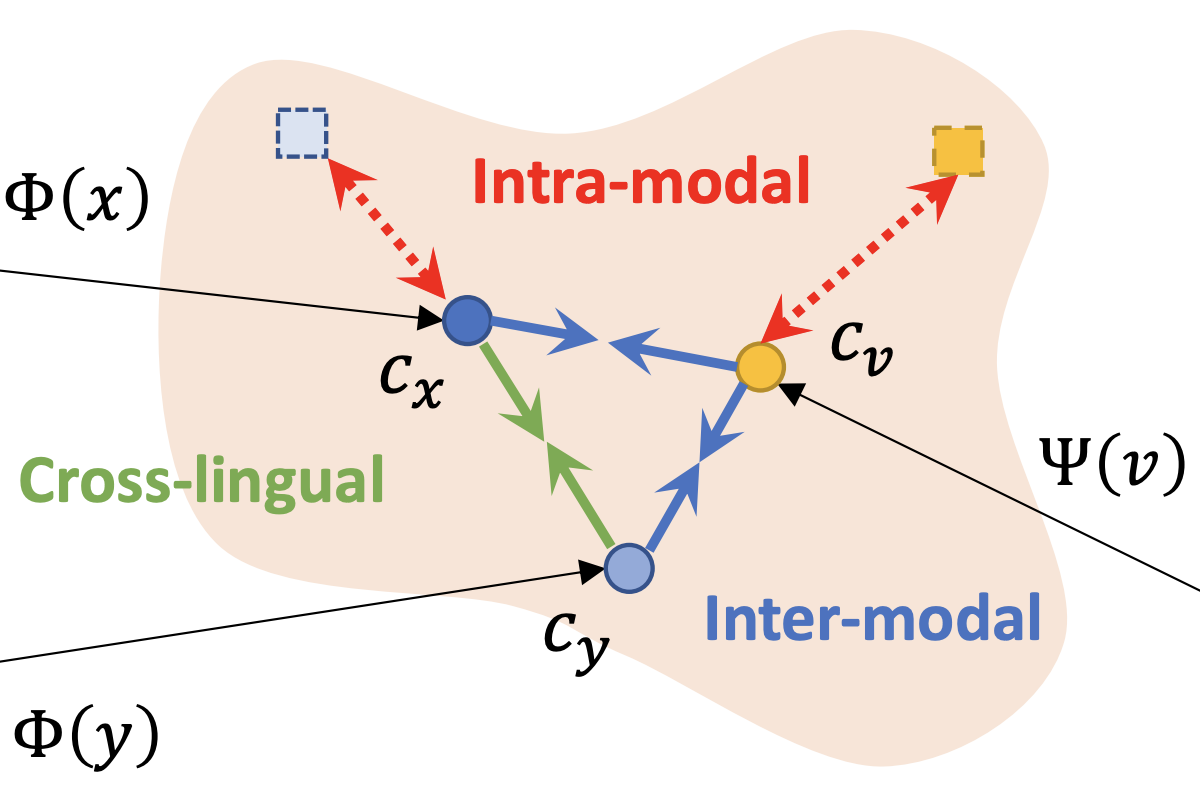
Mandela Patrick*, Po-Yao Huang*, Yuki M. Asano*, Florian Metze, Alexander Hauptmann, João F. Henriques, Andrea Vedaldi ICLR, 2021 (Spotlight) slides | poster | bibtex | talk We use a generative objective to improve the instance discrimination limitations of contrastive learning to set new state-of-the-art results in text-to-video retrieval. |

|
Yuki M. Asano*, Mandela Patrick*, Christian Rupprecht, Andrea Vedaldi NeurIPS, 2020 code | slides | poster | bibtex | talk Unsupervisedly clustering videos via self-supervision. We show clustering videos well does not come for free from good representations. Instead, we learn a multi-modal clustering function that treats the audio and visual-stream as augmentations. |
 
|
Ruth Fong*, Mandela Patrick*, Andrea Vedaldi ICCV, 2019 (Oral) code | slides | poster | bibtex | talk We introduce extremal perturbations, an novel attribution method that highlights "where" a model is "looking." We improve upon Fong and Vedaldi, 2017 by separating out regularization on the size and smoothness of a perturbation mask from the attribution objective of learning a mask that maximally affects a model's output; we also extend our work to intermediate channel representations. |
|
Great template from Jon Barron
|